Linux File System: Virtual File System (VFS) Layer | Part 3
Before getting into the business of the day, let me quickly establish some points 📌.
- This is not a beginner level tutorial but anyone can follow up as long as learning isn’t a problem.
- I’m not a Linux file system guru so I can’t basically cover everything here but I’ll try my best.
- All mistakes, inaccuracies and falsehood made are my fault and I take responsibility for them. At the same time please point them out. Loud and clear.
It’s a normal instance for Linux systems to contain multiple mounted file systems. These file systems usually have different implementation details on how they manipulate data.
Lets assume a Computer has NTFS (native windows file system) and ext4 file systems mounted at different namespaces on a disk drive together with a network file system (NFS) for transferring data between a network and a user-space program that needs to interface with these file systems.
One problem arising from this instance is that if a user-space client requires to interact among these file systems, the kernel would then need to define a 1:1 mapping between the file system handling mechanism and file system. i.e. One unique method for connecting various file systems with the kernel. A programmer might quickly note that defining multiple manipulation strategies automatically leads to code duplication or duplication of actions.
Another problem is that these file systems would also have a hard time communicating with one another. This means our user-space client can’t pipe data from one file system into another, do some filtering and output modified data using another file system. At every point of piping the kernel would have to initiate complex procedures to handle file system switching.
3 file systems above translates to 3 different kernel implementations. So what if there were 20 different file systems? You do the math.
How do we the go about the problem?
This problem is solved with the help of the VFS (Virtual File System).
So what’s the VFS?
VFS (Virtual File System aka Virtual File Switch) is actually a wrapper around the kernel low-level file system interface. It abstracts all the file handling mechanisms into one procedure that all user-space programs and file system types must conform too.
Our very good ol’ Wikipedia the free encyclopedia gives a succinct explanation:
A virtual file system (VFS) or virtual filesystem switch is an abstract layer on top of a more concrete file system. The purpose of a VFS is to allow client applications to access different types of concrete file systems in a uniform way. A VFS can, for example, be used to access local and network storage devices transparently without the client application noticing the difference.
Need a mental model?
Here’s one I got for you at opensource free-of-charge:

A computer having multiple file systems can interact and coexist with themselves by communicating with the VFS which now poses as a common file system interface. Generic syscalls like write(), read() can then made by user-space programs which is then interpreted by the VFS and sent to the file system for the appropriate command to be executed.
Problem solved!!.
The file system abstraction layer
We understand that different file system come with different features, implementations, quirks and similarities too!!. And we know that the abstraction layer makes these things work together seamlessly when used with syscalls.
So how does this abstraction layer work?
The abstraction layer is possible because the VFS has a common file model that understands the different features, quirks of these file system and also represent the file system’s general feature set and behavior. The data structures (files and directories) and interface supported by the file systems are defined by the abstraction layer.
The filesystems mold their view of concepts such as “this is how I open files” and “this is what a directory is to me” to match the expectations of the VFS. The actual filesystem code hides the implementation details. To the VFS layer and the rest of the kernel, however, each filesystem looks the same. They all support notions such as files and directories, and they all support operations such as creating and deleting files.
The kernel doesn’t need to understand the intricacies of the computer’s file system. All of these have been abstracted away from the kernel by the VFS.
So a user-space program which uses the write() syscall doesn’t execute a syscall subroutine in the kernel immediately, rather a generic syscall from the VFS handles the request and determines which file system is been called via the file descriptor. The generic syscall automatically initiates the write() call that’s part of the particular file system implementation.
The above explanation can be summarized with the code snippet and diagram below:
ret = write (fd, buf, len);
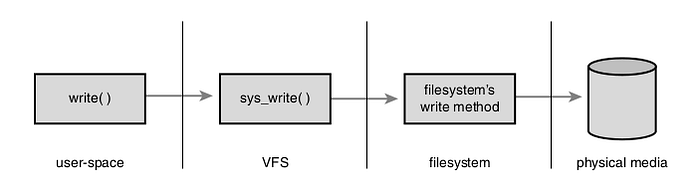
The write() call attempts to transfers the data in buf into the location indicated by fd (location of receiving file system) by invoking sys_write() in the VFS which then triggers the appropriate file system with the help of fd (file descriptor)
Examples of file systems supported by Linux VFS includes
- Disk-based filesystems: ext2, ext3, ext4, MINIX, ubifs, VxFS, sysv, ufs, UDF DVD, ISO9669 CD-ROM
- Network filesystems: nfs, coda, afs, cifs, ncp
- Special filesystems: cgroups, tmpfs, devtmpfs, proc, Sysfs etc.
NB: Check the fs folder in your Linux machine’s kernel repository to see supported file systems.
Examples of system calls supported by VFS
- Filesystem: mount(), umount(), umount2(), sysfs(), statfs(), fstatfs(), statfs64(), fstatfs64(), ustat()
- Directories: chdir(), fchdir(), getcwd(), mkdir(), rmdir(), getdents(), getdents64(), readdir(), link(), unlink(), rename() etc
- Files: chown(), fchown(), lchown(), fchmod(), chmod() etc
- Links: readlink(), symlink()
A recap on what Linux file systems are
File system in Linux systems means the structured representation of saved data in a disk drive that follows specific (hierarchical) format all within a single namespace.
We can also have multiple namespaces within a disk drive but they are all hooked up or mounted at a particular point within the disk drive. The top most point of the main namespace where all other namespaces are mounted on is called root.
This is unlike Windows systems that represent disk drives in form of drive letter such as C:, E: etc (this file system design is inferior to Linux’s). The situation leads to a phenomenon call “hardware leak”. You can look that up on Google.
Abstraction related to Linux file systems includes:
- Files
- Directories
- Inodes
- Mount points
PS: Calling directories as folders usually elicit unpleasant reactions from Linux users because its a Windows thing. So beware!
Files are represented as an ordered string of bits while directories consists of files. Directories can also nest other directories called sub-directories. A collection of nested directories can be referred to as a path. The components within this path is called a dentry. Therefore directories, sub-directories and files within a path are know as dentries
And we also know that information about a particular file such as owners, permissions etc are stored as a datastructure known as inode index node. Inodes don’t contain file names. There are other things like superblocks etc.
You can find more about file systems here
VFS and its associated objects (The fun part 🥳)
VFS is object oriented.
Well, that’s a partial lie. Remember when we talked about the common file model that’s able to interact with these multiple file systems? The VFS implements this model as primary objects. But we know C language doesn’t support OOP so we make use of structures as a hack. This way, we are kinda able to assign object oriented capabilities to this model.
Structures == Objects in Linux VFS parlance
In this section we will talk about these objects and their datastructures.
The primary objects represented by the VFS includes:
- File object: This represents an open file as associated with a process
- Superblock object: This represents the entire file system metadata
- Inode object: Represents metadata about a particular file
- Dentry object: This represents a directory object.
The primary objects represent the file abstractions that were familiar with in normal file systems.
NB: This primary objects are logical entities within the VFS as opposed to the actual superblocks, inodes contained with specific part of a disk drive.
NB: The primary objects were built with a Unix mindset but other file systems e.g FAT32 that don’t support these objects model their datastructures to suit the common file model of the VFS.
In Robert Love’s Linux kernel development book, he notes that
“people often miss this, or even deny it, but there are many examples of object-oriented programming in the kernel. Although the kernel developers may shun C++ and other explicitly object-oriented languages, thinking in terms of objects is often useful. The VFS is a good example of how to do clean and efficient OOP in C, which is a language that lacks any OOP constructs.”
He further notes that
“objects refer to structures — not explicit class types, such as those in
C++ or Java.These structures, however, represent specific instances of an object, their associated data, and methods to operate on themselves.They are very much objects.”
The kernel needs to manipulate the file system primary objects and it does so by manipulating each of their individual operations object. And we have 4 of them. Namely:
- file_operations object: We know from OOP that objects contain methods. So this objects contains methods that the kernel can invoke to open file. Some are read(), write()
- super_operations object: The kernel uses the methods to invoke meta data about a particular file system in hierarchy. Eg. write_node() and sync_fs(); *write_super() is a pointer that writes to the file system superblock.
- inode_operations object: The kernel can invoke methods associated with this object on specific file. It can determine set permissions, owner, group and other meta data belonging to a file. Eg. create() and link()
- dentry_operations object: This contains methods that kernel can call on a particular directory. Eg d_compare() and d_delete()
We should also note that each mount point in the file system is represented by the vfsmount structure. Each mounted file system is also represented by the file_system_type structure. Even processes have their own structures which describes their associated file system and files.
Let’s take a look at the super_block primary object.
So we know that the superblock stores information about the file system and its object counterpart in the VFS is also used for the same purpose. Infact it maps to the superblock region that’s contained within the disk drive. Check here for a refresher on what superblocks are.
The superblock object is defined as a struct. Remember that we use structs as objects in C. A description for this object can be found within the <linux/fs.h> header file.
And we know that header files don’t necessary contain C code although they could, but most of the time, they usually contain directives utilized by the C compiler when executing C programs. The actual C code related to the directives specified in the header file resides in a library file or exists as a precompiled binary code. That’s why the code utilized by for manipulating superblocks resides within fs/super.c.
So a mounted file system automatically,
- triggers alloc_super() function,
- reads the file system data contained within the superblock of the disk drive and
- transfers it into the super_block object of the VFS.
The <linux/fs.h> that describes the super_block structure is really big and it looks like this:
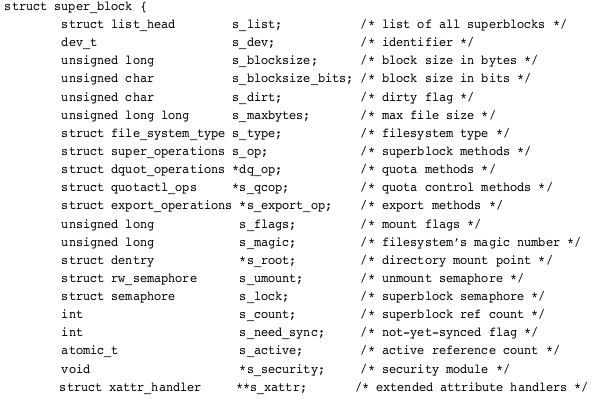

We can see that this super_block struct contains the super_operations that we discussed above.
Let’s take a look at the s_op item of the super_block object
The s_op object is within the super_block header and its also defined within the <linux/fs.h> header file which is the same as that of super_block and it points to the super_block operations table which is contained by struct super_operations. You can check for all this in the image above.
Here is the super_operations struct


Before I further go into the details of this, let me point 😊 out something.
Each item within the super_operations struct is a pointer to a function that operates on a super_block object.
Therefore, super_operations object or structure is actually a structure of pointers. And recall when we said operations contain methods that the kernel uses in manipulation. The pointers residing within the super_operations struct point to functions and methods that operate on the parent object which is the super_block. Magic!
Look, I don’t know how you see this, but it feels like a type recursion to me. It actually isn’t though.
Let’s see the pointers pointing.
sb->s_op->write_super(sb);
sb (super_block) points to a superblock within the particular mounted filesystem which then points to s_op which further points to the super_operations struct and follows up to the write_super(). write_super() accepts the super_block as parameter aka parent object. You see.
super_block had to go through all this hassle just to call write_super() which still accepted super_block as a paremter. This is basically because C lacks OOP constructs. With Python, C++ or any OOP langauage we could easily have achieved this task using a simple sb.write_super().
Other VFS objects like inode object, dentry object have their own associated operations and methods of which I just can’t go through in this article.
Wheew. So we’ve come along talking about file systems and a few things in it.
If you genuinely read up to this point then congrats because you already possess the traits of becoming a great computer hacker. Also, I’m of the assumption that curiosity led you to this point so I suggest you read-up further on the other objects not talked about here and also expatiate the knowledge you gained here.
I’ll leave some links to resources that I’ve found helpful. I do hope you make out time to open them. They are good for you.
Thanks to you all readers and I hope I’ve been able to spark your bulb for an affinity to Linux and also to @Curious Paul for making corrections and edits.
And also, please drop your comments below and a clap 👏 beside.
Resources and References
https://www.amazon.com/Linux-Programming-Interface-System-Handbook-ebook/dp/B004OEJMZM/ref=sr_1_1?dchild=1&keywords=Linux+programming+interface&qid=1588274140&sr=8-1 [Chapter 3 to understand Syscalls]
https://medium.com/@emmanuelbashorun/a-deep-dive-into-the-linux-filesystem-part-1-d06d365d42bb [PART I]
https://medium.com/@emmanuelbashorun/a-deep-dive-into-the-linux-filesystem-part-2-87999610062f [PART II]